
Understanding LLM Integration in Modern Search Engines: A Beginner’s Guide
How LLMs Work for Search: An Enterprise Guide to Generative Engine Optimization
Key Takeaways
- Fundamental Shift: Large Language Models (LLMs) operate on next-token prediction and probabilistic generation, not traditional keyword indexing. This requires a new optimization discipline: Generative Engine Optimization (GEO).
- Retrieval-Augmented Generation (RAG): LLMs use RAG to fetch real-time data, but this is not automatic. Optimization involves forcing AI crawlers to re-index fresh content through aggressive schema updates and contributions to public knowledge graphs.
- Commercial Impact: The presence of an AI Overview in search results can cause a 68% drop in paid search CTR. However, LLM-referred traffic converts at a high 18% rate, making visibility a critical commercial objective.
- Actionable Optimization: Winning citations in AI Shopping and Maps requires meticulous
ProductandLocalBusinessschema. The goal is to make your brand’s offerings machine-readable entities. - Automated Execution: For enterprises, manual monitoring is unscalable. Automated workflows (e.g., using n8n) are necessary to track and fix un-cited brand mentions across the 17+ different AI models that comprise the modern search landscape.
Key Takeaways: Optimizing for the New AI Search
Fundamental Shift
LLMs operate on probabilistic generation, not keyword indexing. This requires a new discipline: Generative Engine Optimization (GEO).
Retrieval-Augmented Generation (RAG)
LLMs use RAG for real-time data, but this isn’t automatic. Optimization involves forcing re-indexing via schema and knowledge graph updates.
Commercial Impact
While AI Overviews can drop paid CTR, LLM-referred traffic converts at a high 18%, making visibility critical.
Actionable Optimization
Winning citations in AI Shopping and Maps requires meticulous Product and LocalBusiness schema to make your brand a machine-readable entity.
Automated Execution
Manual monitoring is unscalable. Automated workflows are necessary to track and fix un-cited mentions across the 17+ AI models in the search landscape.
Introduction: The End of Search As We Know It
The digital marketing landscape is experiencing a seismic shift, underscored by a jarring industry statistic: paid search click-through rates (CTR) plummet by a staggering 68% when an AI Overview is present in search results, according to an analysis by ContentGecko. For Marketing Directors in the competitive US enterprise market, this isn’t just a number—it’s a direct threat to established traffic funnels and a clear signal that the old playbook is obsolete.
📊 Impact on Paid Search
According to analysis by ContentGecko, paid search click-through rates (CTR) drop by an average of 68% when a search result page includes an AI Overview. This highlights the urgent need for a new optimization strategy.
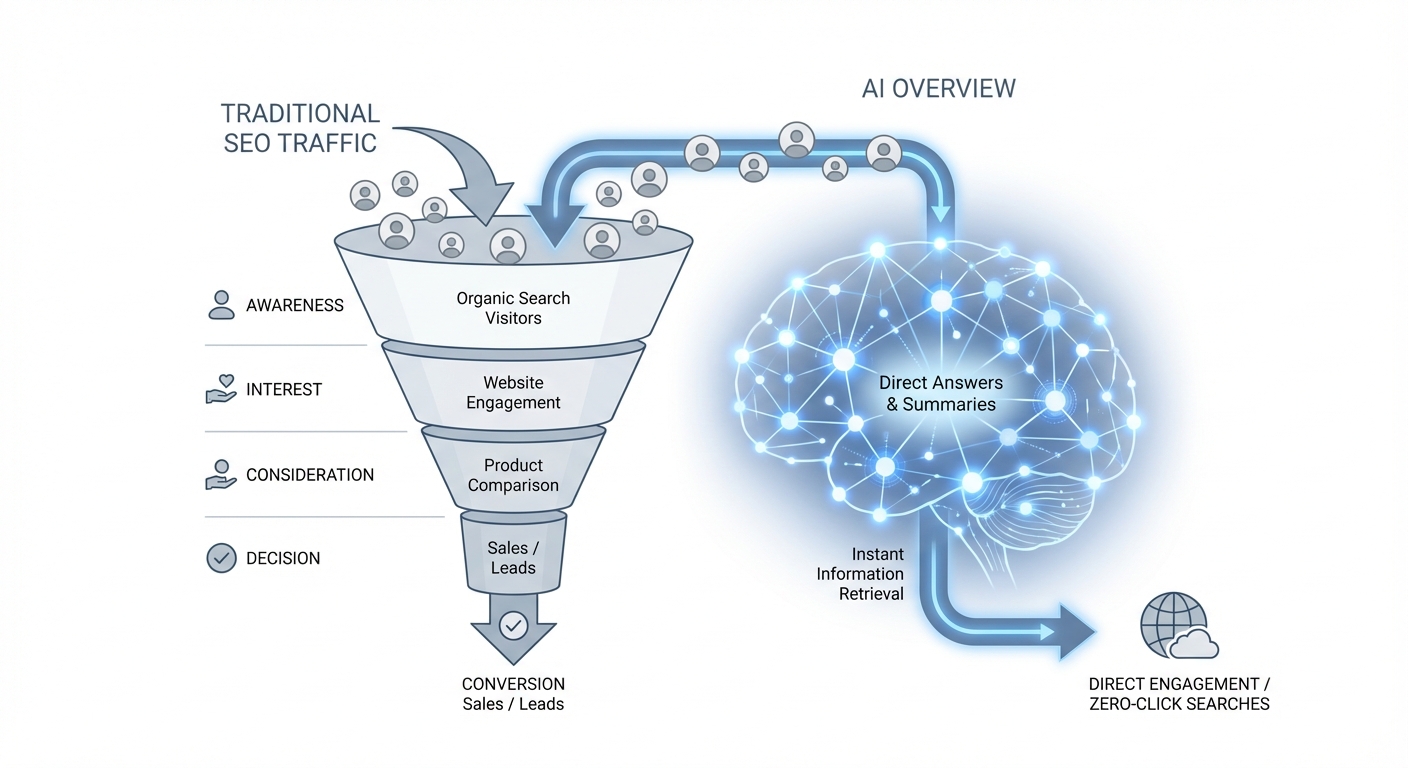
As you watch traditional search performance decline, the urgent question becomes how to secure brand citations in the generative answers of ChatGPT, Claude, and Perplexity. To understand how LLMs work for search in this new context requires moving beyond academic theory and into operational strategy. This guide introduces a new methodology: automated action plans that actively track and optimize for visibility across more than 17 distinct AI models, turning passive monitoring into proactive revenue generation.
- Author: Pedro Spota, Director of Growth at AI Rankia
- Bio: Pedro designs and implements data-driven growth systems tied to revenue and cost reduction. He orchestrates a team of 200+ AI agents focused on marketing, sales, and SEO, leveraging advanced frameworks like n8n to optimize conversion lift.
- LinkedIn: https://linkedin.com/in/pedrospota
- Transparency Disclosure: This guide is based on AI Rankia’s proprietary tracking data across 17+ global AI models and peer-reviewed research on Large Language Model retrieval mechanisms. The data insights presented are the result of our internal analysis and have not been generated by AI.
From Keywords to Probabilities: Why LLMs Don’t “Search” the Web
When marketing leaders ask how LLMs work, they often receive academic answers about neural networks, which misses the critical operational gap: LLMs do not “search” or “crawl” the web like Google. At their core, they are next-token predictors, calculating the most probable next word in a sequence based on statistical patterns in their training data. As tech expert Neo Kim notes, it’s more accurate to treat LLMs as “probability predictors based on training data, not fact-based search tools.”
💡 Expert Insight: A Shift in Thinking
As tech expert Neo Kim notes, it’s more accurate to treat LLMs as ‘probability predictors based on training data, not fact-based search tools.’ This distinction is the foundation of Generative Engine Optimization (GEO).
This fundamental difference means traditional SEO tactics focused on keyword density and backlinks are insufficient. The new discipline is Generative Engine Optimization (GEO), which focuses on influencing these probabilistic outputs. The commercial stakes are high; data from Search Engine Land indicates that LLM-referred users convert at a remarkable 18% rate, proving this is high-intent traffic worth capturing.
📊 High-Intent Traffic
Data from Search Engine Land reveals that traffic referred from LLM-generated answers converts at an 18% rate. This demonstrates that users who engage with AI answers are high-intent and commercially valuable.
Traditional Indexing vs. Token Probability
Traditional SEO vs. Generative Engine Optimization (GEO)
| Option | Pros | Cons |
|---|---|---|
| Traditional SEO | Operates on a clear system of crawling, indexing, and ranking based on relevance and authority signals. | Less effective for influencing AI-generated answers which don’t rely solely on ranked links. |
| Generative Engine Optimization (GEO) | Directly influences the probabilistic outputs of LLMs by embedding facts into their knowledge base via structured data. | Requires a deeper technical understanding of machine readability and entity recognition. |
Traditional search engines like Google operate on a clear principle: crawl the web, index content, and rank pages based on relevance and authority signals. SEO professionals have spent decades mastering this system of information retrieval (IR).
An LLM, however, operates on token probability. It deconstructs language into “tokens” (words or parts of words) and learns the statistical relationships between them from a massive training dataset. This represents a significant evolution from classic neural IR models, as detailed in comprehensive surveys on the application of LLMs to information retrieval (Zhu et al., 2023). When you ask an LLM a question, it doesn’t search an index; it generates a response by predicting the most likely sequence of tokens to follow your prompt.
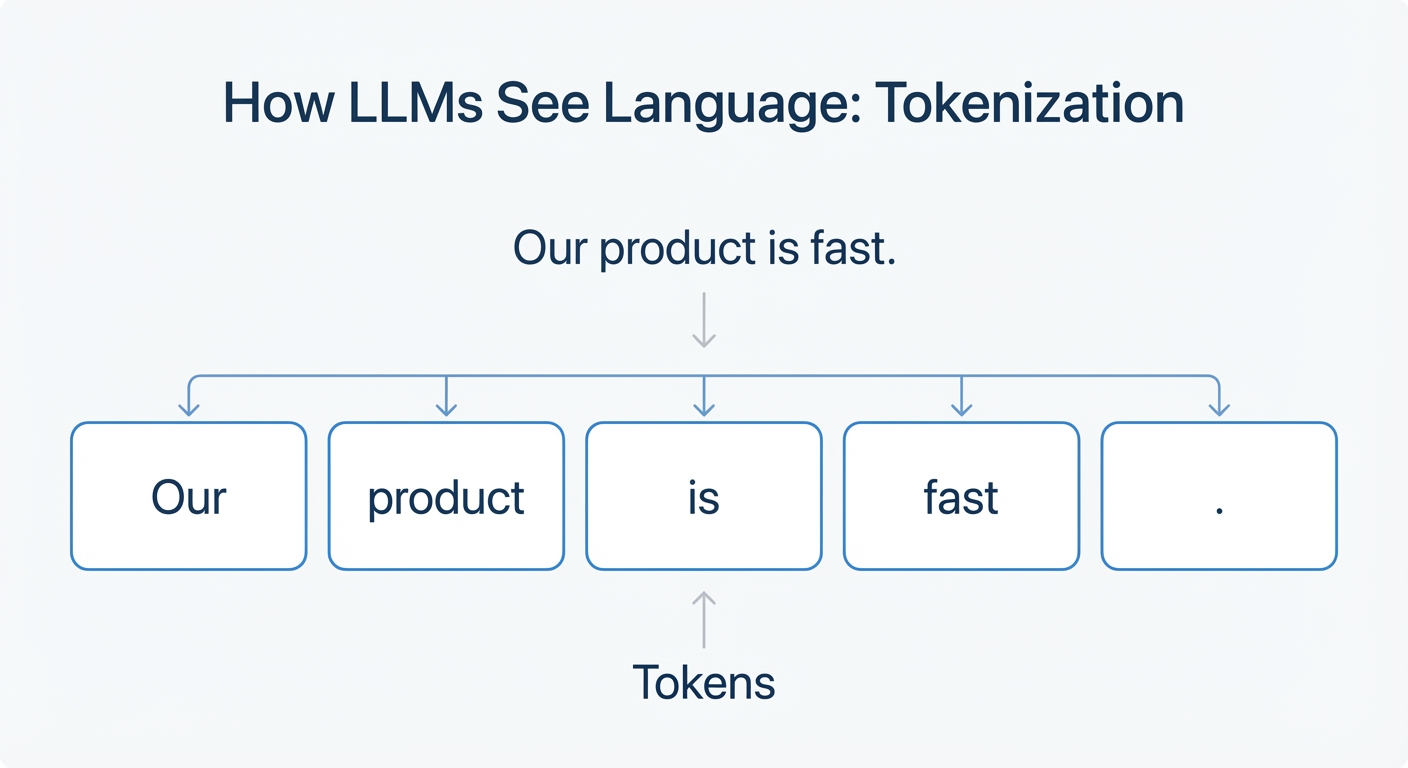
This distinction is crucial for optimization. Instead of optimizing for a crawler to find keywords, you are now optimizing for your brand’s facts and key messages to be embedded in the LLM’s training data with high statistical weight. The goal is to make your brand’s information the most probable and authoritative “next token” when a user asks a relevant question.
Structuring Content for Attention Mechanisms
To make your content influential in a probabilistic model, you must structure it for an LLM’s “attention mechanisms.” These mechanisms allow the model to weigh the importance of different tokens when generating a response. As LinkedIn professional Jairo Guerrero advises, marketers should “structure content to align with LLM attention mechanisms rather than traditional search engine indexing.”
📝 Use Declarative Sentences
State facts unambiguously to provide clear, citable information. Example: ‘Product X features a 16-hour battery life.’
📊 Employ Structured Formats
Use bullet points, numbered lists, and tables to break down complex information into machine-readable chunks.
🏢 Emphasize Named Entities
Consistently associate your company, product, and personnel names with specific attributes and facts to increase citation probability.
Research into neural information retrieval highlights that context and structure are paramount for long-document understanding (Guo et al., 2020). A common mistake is writing long, narrative prose that buries key facts. Instead, structure your content with machine readability in mind:
Machine-Readability Checklist
Do: Use Clear Headings
Use H2s and H3s that clearly state the topic of the following section.
Don’t: Bury Facts in Prose
Avoid long, narrative paragraphs that hide key data points and specifications.
Do: Implement Schema Markup
Use structured data like Product, Organization, and LocalBusiness schema.
Don’t: Use Ambiguous Language
Avoid marketing jargon in favor of direct, factual statements.
- Use clear, declarative sentences that state facts unambiguously (e.g., “Our product X is designed for enterprise-level data analysis.”).
- Employ structured formats like bulleted lists, numbered steps, and tables to break down complex information.
- Emphasize named entities—your company name, product names, key personnel, and locations.
By consistently and clearly associating these entities with specific attributes and facts, you increase the probability that the LLM will cite your brand correctly. This isn’t about gaming an algorithm; it’s about providing clear, unambiguous data that makes your brand the most reliable source for the model to reference.
The RAG Dilemma: How to Force-Feed Fresh Data to AI Models
Standard explanations of AI search often mention Retrieval-Augmented Generation (RAG) but provide a sanitized, high-level definition. This leaves US enterprises with a critical unanswered question: how can we actively trigger live searches so our brands aren’t penalized by an LLM’s knowledge cutoff date? The generic advice falls short because it doesn’t address the practical execution needed to force an update.
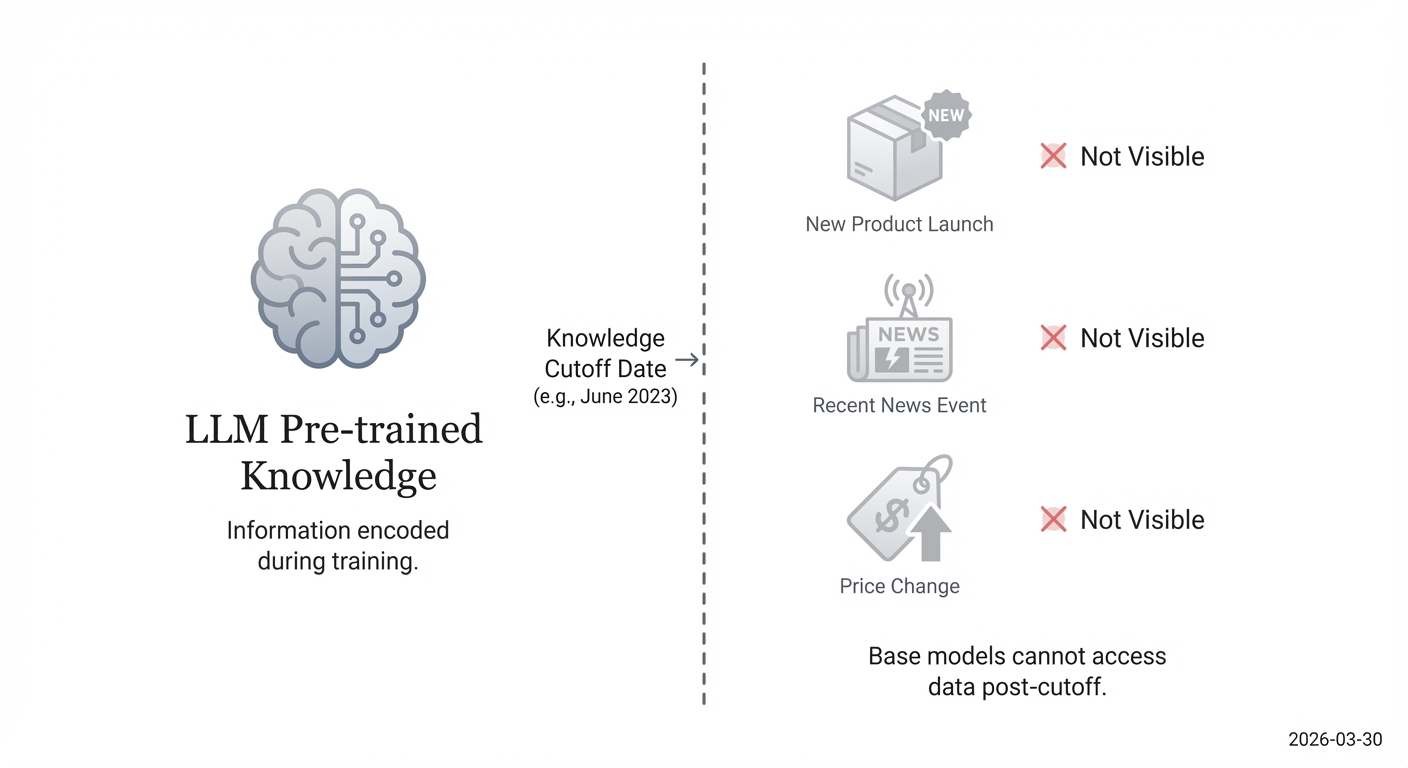
Most queries are answered using pre-trained data, making brands with recent product launches invisible. As marketing expert Jeremy Moser points out, a key strategy is to “focus on crafting prompts that trigger live searches for fresh content.” Our advantage at AI Rankia lies in an automated action plan that actively prompts AI crawlers to re-index fresh content and schema. This ensures that when an LLM decides to retrieve external information, your most current data is what it finds.
The Mechanics of RAG in AI Search
Retrieval-Augmented Generation (RAG) is the process that allows an LLM to supplement its pre-trained knowledge with external, real-time information. It’s a multi-step pipeline that bridges the gap between static knowledge and the dynamic web.
- Retrieval: When a prompt requires information beyond the LLM’s training data, the system first retrieves relevant documents from a search index. This step often uses a hybrid approach, combining traditional lexical search like BM25 with modern vector search.
- Re-ranking: The retrieved documents are then passed through a re-ranking model. As a 2023 EMNLP paper found, advanced LLMs can excel as re-ranking agents, assessing documents for relevance and factual accuracy in the context of the query (Sun et al., 2023).
- Generation: Finally, the original LLM uses the top-ranked documents as a source of truth to generate its answer. This grounding in retrieved documents is a key technique to mitigate hallucinations, as demonstrated by frameworks like LitLLM.
For enterprises, influencing this process means ensuring your content is what gets retrieved and ranked highest. Surprisingly, studies show that the classic BM25 algorithm can still achieve a Precision@1 score of 0.8026, matching more complex models on certain benchmarks (Sinha et al., 2015). This underscores the continued importance of clear, keyword-relevant text, even in a vector-first world.
📊 The Enduring Power of Keywords
Even in the age of vector search, classic keyword-based algorithms like BM25 can achieve a Precision@1 score of 0.8026, matching more complex models in some cases. This highlights the continued importance of clear, keyword-relevant text in the retrieval step of RAG.
Forcing Real-Time AI Crawling
🔄 Aggressive Schema & Sitemap Updates
Update the `dateModified` property in your schema and the `
🌐 Contribute to Public Knowledge Graphs
Create and maintain an accurate Wikidata entry for your organization, products, and executives to feed authoritative data to LLMs.
🔗 Strategic Authority Linking
Acquire links from trusted entities like academic institutions and respected industry publications to act as an endorsement for RAG systems.
You cannot directly command an LLM’s crawler to re-index your site. However, you can create strong signals that encourage it to fetch fresh data when performing RAG. The most common mistake is to update content and simply wait. A proactive strategy is required.
- Aggressive Schema & Sitemap Updates: Go beyond a one-time schema implementation. Every time content is updated, ensure the
dateModifiedproperty in your schema and the - Contribute to Public Knowledge Graphs: LLMs trust established, third-party knowledge graphs like Wikidata. By creating and maintaining an accurate Wikidata entry for your organization, products, and key executives, you are feeding authoritative, structured data directly into a source many LLMs use for fact-checking and entity recognition.
- Strategic Authority Linking: Reframe your backlinking strategy. Instead of chasing link volume, focus on acquiring links from sources that are themselves considered authoritative entities (e.g., academic institutions, respected industry publications, government sites). For a RAG system, a link from a trusted source acts as a powerful endorsement, increasing the likelihood your content will be retrieved and trusted.
Winning the Transactional Query: Optimizing for AI Shopping & Maps
Generic advice for Generative Engine Optimization often boils down to “write high-quality content.” This counsel is dangerously incomplete for enterprises competing in e-commerce and local services. It misses the specific schema enhancements and entity recognition required for LLMs to cite products in AI Shopping carousels and locations in AI Map integrations. With paid CTR dropping 68% in the presence of an AI Overview, failing to appear in these new generative formats is not an option.
Your brand must be machine-readable at a granular level. This is where specialized tools for AI Shopping, Maps, and schema enhancement become critical. It’s not just about content; it’s about structured data that explicitly defines your products and locations as distinct entities. The Hacker News community has observed this shift, noting that “users increasingly prefer Perplexity for summarization over traditional search, bypassing Google entirely for complex queries.” To be included in these summaries, your data must be structured for machines.
💡 From the Community: Shifting User Behavior
The Hacker News community has observed that users are increasingly turning to tools like Perplexity for complex queries, bypassing traditional search engines entirely. This trend underscores the importance of being visible within these new generative platforms.
Entity Recognition for AI Maps
To get your business cited in an AI-powered map summary (e.g., “What are the best Italian restaurants in downtown Boston with outdoor seating?”), the LLM needs to recognize your business as a distinct entity with specific attributes. This goes far beyond having your address on your website. The key is robust LocalBusiness schema markup.
Essential LocalBusiness Schema for AI Maps
@type: LocalBusiness
Explicitly declares your entity as a local business.
name, address, telephone
Must be consistent (NAP) across all online directories.
geo (latitude/longitude)
Provides precise coordinates for mapping services.
openingHours
Lists operating hours in a machine-readable format.
A common mistake is incomplete or inconsistent NAP (Name, Address, Phone) information across online directories. For an LLM, this inconsistency reduces trust and lowers the probability of your business being cited. A best-in-class implementation should include:
-
@type: LocalBusiness: Explicitly declare the entity type. -
name,address,telephone: Ensure these are identical everywhere online. -
geo: Provide precise latitude and longitude coordinates. -
openingHours: List your hours in a machine-readable format. -
hasOfferCatalog: Connect to a catalog of your services or menu items.
By providing this rich, structured data, you are feeding a machine the exact facts it needs to confidently recommend your location over a competitor’s.
Schema Enhancement for AI Shopping
Similarly, for your products to appear in AI Shopping results, they must be defined with meticulous Product schema. When a user asks, “Show me 14-inch laptops under $1000 with at least 16GB of RAM,” an LLM uses RAG to find products that match these attributes. It will only find yours if your product data is explicitly structured.
Critical Product Schema for AI Shopping
@type: Product
The basic declaration for your item.
name, description, sku
Core identifiers that uniquely define the product.
brand
Links the product to a brand entity (via Organization schema).
offers (Offer type)
Crucial nested schema containing price, currency, and availability (e.g., InStock).
A robust Product schema implementation includes:
-
@type: Product: The basic declaration. -
name,description,sku,image: Core product identifiers. -
brand: The brand entity, linked to anOrganizationschema. -
offers: This is critical. It must be anOffertype containing:
* price and priceCurrency
* availability (e.g., InStock, OutOfStock)
* priceValidUntil
Failing to nest the price and availability within an Offer schema is a frequent error that renders the data invisible to many AI shopping aggregators. By structuring every product attribute correctly, you make your inventory directly queryable by generative AI.
Beyond Monitoring: An Enterprise Action Plan for Automated AI Visibility
The standard advice for adapting to AI search is to “monitor your rankings,” which often translates to manually typing queries into ChatGPT and recording the results. This passive approach is unscalable and ineffective for an enterprise. The real gap is the chasm between passive monitoring and deploying automated action plans that can fix un-cited brand mentions across the fragmented landscape of US and international AI models.
The commercial stakes are enormous, with keywords like “ai search engine optimization” commanding a $21.00 CPC and “healthcare ai” at $5.41. Missing out on these citations is a direct loss of high-value traffic. AI Rankia closes this gap by using n8n workflows and a fleet of AI agents to execute Generative Engine Optimization (GEO) at scale. Instead of just reporting a brand isn’t cited, our system automatically identifies the content or schema gap and deploys a fix.
This mirrors the internal strategies of tech giants. As Databricks advises, effective LLM evaluation requires diverse, representative datasets for multi-domain coverage, a principle we apply to ensure brand visibility across all relevant contexts.
| Tool Type | Core Feature | Best For | Limitation | Automation Level |
|---|---|---|---|---|
| Traditional Rank Trackers | Keyword Positions | Legacy SEO | Cannot track ChatGPT/Claude | Manual |
| Passive AI Monitors | Share of Voice | Reporting | No execution capabilities | Manual |
| AI Rankia Action Plans | n8n Agent Workflows | Enterprise GEO | Requires schema overhaul | Fully Automated |
Evolution of SEO Monitoring Tools
| Option | Pros | Cons |
|---|---|---|
| Traditional Rank Trackers | Tracks keyword positions on legacy search engines. | Cannot track visibility in ChatGPT, Claude, or Perplexity. |
| Passive AI Monitors | Reports on Share of Voice in AI answers. | Provides data but no execution or remediation capabilities. |
| Automated Action Plans (AEO) | Uses agentic workflows (e.g., n8n) to automatically detect and fix citation gaps. | Requires significant schema and system integration. |
Deploying n8n Workflows for Automated Execution
Automated Execution Optimization (AEO) moves beyond simple tracking. Using a platform like n8n, we build workflows that connect AI model monitoring with content management systems. For example: an automated workflow queries Perplexity daily for “best CRM for manufacturing firms” and parses the response to check if our client is cited.
💡 Definition: Automated Execution Optimization (AEO)
AEO is a new discipline that moves beyond passive monitoring. It involves using automated workflows and AI agents to connect AI model tracking directly with content management and development systems, enabling the system to automatically fix citation and data gaps as they are discovered.
If the brand is missing, the workflow triggers a multi-pronged response. It might use an API to directly update the product’s schema, adding “Manufacturing” to the applicationCategory property. Simultaneously, it could create a Jira ticket for the content team to develop a new case study highlighting a manufacturing client. The success of these fixes is then validated using domain-specific evaluation metrics like F1 score and exact match. This creates a closed-loop system where detection immediately leads to remediation, operating 24/7.
Securing US Enterprise Online Presence
For a large US enterprise, securing its online presence is no longer about ranking on ten blue links. It’s about ensuring factual accuracy and consistent citation across a fragmented ecosystem of 17+ AI assistants, search engines, and integrated apps. This requires a comprehensive AI Reputation Management strategy.
A manual approach is impossible when dealing with multiple product lines, global markets, and a constant stream of new marketing initiatives. An automated system is required to track how the brand is represented for head terms, long-tail queries, and product comparisons. By deploying automated agentic workflows, enterprises can move from a reactive posture—fixing incorrect AI-generated answers after a customer complains—to a proactive one, ensuring the underlying data is correct before the AI ever formulates a response.
Frequently Asked Questions (FAQ)
- How do large language models work in search engines?
LLMs work in search by generating probabilistic answers rather than ranking indexed web pages. Using models like Retrieval-Augmented Generation (RAG), they first retrieve relevant documents from a web index and then synthesize that information to construct a conversational, summary-style answer. This shifts the optimization focus from keywords to structured data and entity recognition.
- What is an LLM search engine?
An LLM search engine is a platform like Perplexity or Google’s AI Overviews that uses a large language model as its primary interface. Instead of presenting a list of links, it provides a direct, synthesized answer to a user’s query. These engines often combine their pre-trained knowledge with real-time web search results to provide comprehensive summaries.
- How is SEO for LLMs different from traditional SEO?
SEO for LLMs, or Generative Engine Optimization (GEO), focuses on influencing the data sources an LLM uses, not just ranking on a results page. While traditional SEO targets keywords and backlinks, GEO prioritizes creating clear, factual content and structured schema data. The goal is to become a cited, authoritative source within an AI-generated answer.
- Do LLMs actually search the internet?
Does an LLM Perform a Live Search?
Is query time-sensitive or asks for recent info? Is query outside pre-trained knowledge? 01 No NO: Use Pre-trained Data Only 02 YES: Perform Live Search (RAG) 01 Yes Generate Answer 02 LLMs only perform a live internet search when necessary; many queries are answered using only their static, pre-trained knowledge.
Sometimes, but not always. Many LLM responses are based solely on their static, pre-trained data. They typically perform a live internet search (via RAG) only when a query explicitly asks for recent information, contains time-sensitive keywords (“today,” “latest”), or addresses a topic outside their knowledge base. A common mistake is assuming every query triggers a real-time search.
- What is Retrieval-Augmented Generation (RAG) in AI search?
RAG is a process that allows an LLM to “look up” information from an external source before answering a question. It retrieves relevant documents, re-ranks them for context, and then uses that information to generate a more accurate response. Academic frameworks like LitLLM showcase this modular pipeline to ground LLMs in facts and reduce hallucinations.
- How do I optimize my website for ChatGPT and Perplexity?
Optimize by structuring your content as clear, factual statements and implementing detailed schema markup. Focus on entity recognition for your brand, products, and services. Ensure your information is unambiguous and machine-readable. This increases the probability that models like ChatGPT and Perplexity will retrieve and cite your data as an authoritative source.
- Why is my brand not cited by AI search models?
Your brand may not be cited because your content is unstructured, factually ambiguous, or not seen as authoritative by the model. LLMs prioritize sources that are clear, consistent, and well-supported by structured data (schema) and authoritative third-party signals. If your competitors provide cleaner, more machine-readable data, they are more likely to be cited.
- How does next-token prediction affect search results?
Next-token prediction fundamentally changes search from a retrieval task to a generation task. The LLM constructs an answer word by word based on statistical probability. Your content’s influence depends on how strongly your brand’s information is weighted in the model’s training data, making factual accuracy and clarity more important than traditional keyword density.
Limitations, Alternatives & Professional Guidance
The strategies outlined in this guide represent the cutting edge of Generative Engine Optimization and involve significant technical overhead. Optimizing for 17+ different AI models requires specialized expertise in areas like hardware-accelerated retrieval, lightweight neural ranking models, and automated workflow management.
⚠️ Technical Expertise Required
The GEO strategies outlined require specialized expertise in schema architecture, neural ranking models, and workflow automation. For large enterprises, a professional consultation is strongly recommended before undertaking a major overhaul of your systems.
For small businesses with limited resources, alternatives like manual prompt engineering for key queries and implementing basic schema updates can provide some benefit. However, for mid-to-large US enterprises where the scale and fragmentation of the AI search landscape pose a direct revenue threat, automated agentic workflows are a necessity.
Professional Disclaimer: This article provides strategic guidance and should not be considered a substitute for professional consultation. The implementation of enterprise-level schema architecture and automated systems can have significant financial and operational implications. Before undertaking a major overhaul, we strongly recommend you Contact Us to consult with an AEO specialist to assess your specific needs and risks.
Conclusion
The emergence of generative AI in search represents a fundamental paradigm shift, moving the goalposts from traditional keyword indexing to the new frontier of Generative Engine Optimization. For enterprises, understanding how LLMs work is no longer an academic exercise; it’s a commercial imperative. The core mechanisms of next-token prediction and Retrieval-Augmented Generation are now the primary determinants of brand visibility, and failing to adapt exposes your brand to catastrophic traffic loss from zero-click AI Overviews.
The old model of passive monitoring and manual fixes is obsolete. In a fragmented ecosystem of 17+ AI models, the only way to protect and grow your digital presence is to ensure your brand’s data is the most authoritative, structured, and accessible source. This requires moving from reporting problems to automatically executing solutions. For US Marketing Directors ready to automate their visibility in AI Shopping, Maps, and multi-model generative results, the path forward is clear.
Book a demo with AI Rankia today to see how our automated action plans can secure your brand’s place in the future of search.
References
- ContentGecko (2024). AI Overviews Impact on CTR. Source for the statistic that paid search CTR drops 68% when an AI Overview is present.
- Databricks (2024). Best Practices and Methods for LLM Evaluation. Provides enterprise-level context on the importance of diverse datasets for evaluating LLM performance, a principle applied to GEO.
- Guo, J., et al. (2020). A Deep Look into Neural Ranking Models for Information Retrieval. A comprehensive survey on neural IR that provides foundational context for understanding how LLMs process long-form content.
- Hacker News Community (2024). Discussion on Perplexity vs. Google. A community discussion highlighting the user trend of bypassing traditional search for complex queries, underscoring the rise of LLM-native search engines.
- LitLLM (2024). LitLLM: A Toolkit for Research on Retrieval-Augmented Large Language Models. An academic paper outlining the modular RAG pipeline, used here to explain the technical process of grounding LLMs in factual data.
- Search Engine Land (2024). What 13 months of data reveals about LLM traffic growth and conversions. Source for the statistic that LLM-referred traffic converts at an 18% rate, establishing the commercial value of GEO.
- Sinha, A., et al. (2015). An Overview of Microsoft Academic Service (MAS). An academic paper demonstrating the enduring effectiveness of classic retrieval algorithms like BM25, relevant for understanding the hybrid nature of modern RAG systems.
- Sun, W., et al. (2023). Is ChatGPT Good at Search? Investigating Large Language Models as Re-ranking Agents. An EMNLP conference paper providing evidence that LLMs can function effectively as re-ranking agents within a RAG pipeline.
- Zhu, Y., et al. (2023). Large Language Models for Information Retrieval: A Survey. An academic survey that positions LLMs as a significant evolution from previous IR models, contextualizing the shift from keyword indexing to probabilistic generation.